
Deep dive into Deep Research: 12 agents and agent makers compared
The Deep Research challenge: Gemini, Perplexity, Grok, ChatGPT, Make.com, Relay, SmythOS, n8n, Microsoft Autogen, Gumloop & CrewAI…

This issue is in two parts: important news, then a big deep dive. I’d love your feedback on how valuable the deep dive is. Cast your vote now 👇
It’s hard to think that just 3 months ago I was pooh-poohing agents. And, this week, I used an agent…
… to analyse other agents…
… to come up with a best practice agent specification…
… I then used another agent…
… to create an agent…
… using that agent spec…
…which then I now use for my own agent research 🤯

Welcome new subscribers! Such tremendous growth from just a few issues of Making AI Agents: humbly appreciated 🙏
Also thank you existing subscribers for your feedback! You are helping this become the best publication possible.
I’ve had numerous video calls and received great insights from the feedback form.
It’s not too late if you still want to provide feedback, links at the end 👇
Important news
Latest Microsoft Autogen Studio is neat
One of my favourite discoveries this week was the latest version of Microsoft Autogen Studio. Here it shows visually the execution flow of one run.

Language Model tools are becoming richer, more accurate and more powerful with Model Context Protocol (MCP)
Language Model “Tools” are an essential way to improve the quality of language models, through fresher and more accurate information and specialist functionality.
Anthropic’s Model Context Protocol (MCP) is a standard way to access this functionality
For example, imagine you have specialist data, say, house insulation in the UK. Without MCP, all agent systems would need to do custom code to connect to your service. With MCP, there’s a standard way for those agent systems to connect more easily.
It’s a new protocol and aspects such as security still need to be fleshed out (as it was originally designed as a desktop plugin solution to Anthropic Claude).
Prediction: 🔮 I expect to see MCP to rapidly accelerate and become a standard part of the AI Engineering and AI Agents ecosystem. For example accessing proprietary data from data brokers like Redpine will become trivial to implement.
Language Models Never Sleep: Claude 3.7, Grok 3 beta and Google Coding Assistant preview launched
AI Agent intelligence relies on the language model you use. So when language models get smarter, your agent gets smarter.
Anthropic Claude 3.5 has been king on a number of benchmarks (particularly coding) for 7 months now. And the conservatively numbered Claude 3.7 has knocked the socks off that…

X.com’s Grok 3 beta also launched, and is offering some pretty attractive features like built-in Deep Research. Available — at least for now — for free.
Developers are experiencing “bill shock” when using AI coding agents intensely for software development. Google Gemini Code Assist launched a public preview, solving this by making the agent free at least for now.
38 new AI agent makers added to my list 🤯
I added 38 more agent making tools to my agent maker list since last publication 2 weeks ago — on top of the 60 I already had 🤯.
Some are not new (Rasa) and some are (Cloudflare Agents launch 25 Feb):
Beam.
(I’m making a dedicated directory, which I’ll announce soon.)
Other recommended articles
These capture important sentiment around AI Agents.
"AI agents will outmanoevre salespeople by optimizing persuasion" source
"The next 10 years will be about the AI Agent Economy" source
Patterns for agent collaboration: Functional, Communication, Role and Organisation. We saw some in a previous issue, here are some more
Have your say! ✍️ 💬
Want this to be the best newsletter ever? I’d love to get your feedback.
1:1 call: if you’re in North America, UK or Europe, let’s chat! 💬
20 second survey: what’s important to you about making AI agents? ✍️
And now on to the deep dive section. 🤿
What’s Deep Dive? I’m experimenting with offering two sections to my newsletter:
Important News, and
Deep Dive (long form)
Deep Dive is where I dig right into the weeds and share a lot more insight. I’d love to get your thoughts about the value of this structure. Feedback at the end 👇
A Deep dive into deep research agents
NOTE that this article is so long your email may truncate it. So do be sure to click “View Entire Message” or view it online inside Substack to see it all.
Deep Research is all the rage: I mentioned it briefly in the last issue and since then just a short two weeks later, we have everyone scrambling to offer “deep research”. Read on for my Deep Research experience using Google Gemini, ChatGPT, X.com Grok, and Perplexity, along with my experience trying to build a Deep Research agent with Relay, Make, n8n, SmythOS, Autogen and CrewAI.
“Deep Research” is a great example of an agentic process we can learn from:
You give the deep research agent instruction
It goes off, using various tools, spending several minutes or even hours researching various resources
It then brings it together in a comprehensive multi-page report with references.
Deep research is a conversational AI agent that spends minutes or even hours scouring the web then bringing it together making a comprehensive multi-page report.
Tired 🥱: asking an AI for an answer and getting a response quickly
Wired ⚡️: ask an AI for a deep research answer and getting a response really slowly

This first generation of deep research agents are a big improvement over conventional AI conversations.
Below are the commercial Deep Research solutions I could find.
“Tiered” means “allow people to use Deep Research a limited number” at some level, with more access expanding the more you pay.
Google Gemini (naff off you have to PAY)
Perplexity (tiered from free)
Grok 3 beta (tiered from free)
OpenAI (tiered, from ChatGPT Plus as of 25 Feb — this is great because prior to this you had to pay $200/mo for any access to Deep Research at all)
All of them do a far far better job than a normal chat with an AI: in particular they’re much better at the accuracy of the output (though not perfect).


The results: they’re all pretty impressive
They’re all pretty good. I’d say overall, it’s a photo finish between:
Perplexity: the most accurate and best user experience, and
Google Gemini would probably have the most comprehensive response (one research task I did Google searched 668 websites!) … but not always.
BIG caveat: it’s a rapidly evolving space and you’ll probably do well using any of them at this point.
I used them for a range of topics over the past week or so. For this article, I chose a niche topic I know well: AI Agents. This is a great way to evaluate deep research because:
I know the AI Agent space well already
I have a sophisticated task specification (“prompt”) that tries to defend against problems I had in the past with things like including unrelated product types in the results.

In a bit more detail then:
ChatGPT Deep Research: generally has some immediate follow-up questions to clarify the scope. Pretty sensible actually and will definitely end up with a better result. Didn’t really cope well with refinements: eventually it kinda gave up and stopped responding.
Google Gemini: annoyingly doesn’t consolidate the results by default so if there are errors, you now have two separate reports, and the second one is just the changes.
Grok 3: impressive results particularly for a “prerelease beta”. I did find it hardest to get the actual results out of Grok but I’m sure that’ll improve over time.
Perplexity has a nice “Auto” mode where IT decides whether Deep Research is warranted. This is great because the moment you give the user a choice, they’ll get it wrong some of the time. Also some research tasks I did, I found Perplexity was better at deep-linking to precisely the relevant result. E.g. searching for “bulk cacao providers in London”, Gemini confused cacao with cocoa where Perplexity linked right to the precisely result.
They need human review.
None of these tools should be trusted to provide truth straight out the gate. They should be considered a draft that then needs to be carefully reviewed with references provided as I found a number of errors.
For example, they all snuck in products that weren’t AI Agents (e.g. infrastructure like memory or hosting or ops) despite seeing assessments to qualify them or not. Even very specific requirements. E.g.
They’re good for small research tasks (10-20 sites) but reluctant to do larger sets
Almost all my queries were “landscape” questions for competitive analysis and opportunity assessment and the first version of the report would work fine for 10-20 items but it took some coaxing to get it to increase, with varying levels of success.

How do you customise deep research then? Take a guess, go on…
These tools are really useful general purpose research tools. They all have their strengths but they all have one problem in common: they’re opaque. You cannot customise them.
For example, here are some things I’d like to do that I don’t think can be done with simple prompts:
Connect the output automatically to another place such as a Google Spreadsheet instead of a rambling unstructured 10 page doc
Compare against my own data provided in a spreadsheet. Even better, update it directly.
Include searches to paid subscriptions my company has.
Access resources that only work reliably through specialist APIs (e.g. Reddit)
Better access control for users.
So how do you do that? Custom agents, that’s how.
Here I introduce Relay, Make, n8n, SmythOS, Microsot Autogen and CrewAI. This field is rapidly evolving, so even though I had no success with many of these tools, I will be checking regularly and seeing how they improve.
In this first batch of AI agent makers I tried to replicate Deep Research. Milestone 1: basic web search and summarisation.
Sadly, even with that the task proved challenging and I could only make even milestone 1 in two of the tools.
I expect this will change in the coming months and quarters though, so stay tuned!
Relay.app: promising but no deep research yet

Relay is probably the easiest UI to work with and I’m very much looking forward to where Relay goes with their product. HOWEVER my first take on Deep Research failed: “blocked by network security”.
Here’s the issue I encountered:
the first node did a web search (works!), then it sent each URL to a scraper (very clear design 🥇)
The scraper failed because Reddit is notorious for blocking scrapers. So Reddit is a special case that needs to be processed separately.
Next time I’ll try and do some kind of filtering and get special keys for Reddit.
Make.com: confusing opaque errors made it incredibly hard to figure out
First up: Make.com has a completely gorgeous interface 🤤 Just… amazing. And its integration tools are suuuper impressive too. But digging into it, I got stuck with no way out.
This is one of the biggest issues with no code tools: if you get stuck, the nice GUI protecting you from the tech complexity often hinders you from the detail needed to troubleshoot.
n8n.io: no built-in scraping.
N8n is also a really gorgeous, well-designed no code AI agent creator.
Sadly, for Deep Research specifically it didn’t get out the gate because it doesn’t seem to offer any search or scraping tools out of the box.
The only way is as a tool through an LLM (which wouldn’t work for this case).

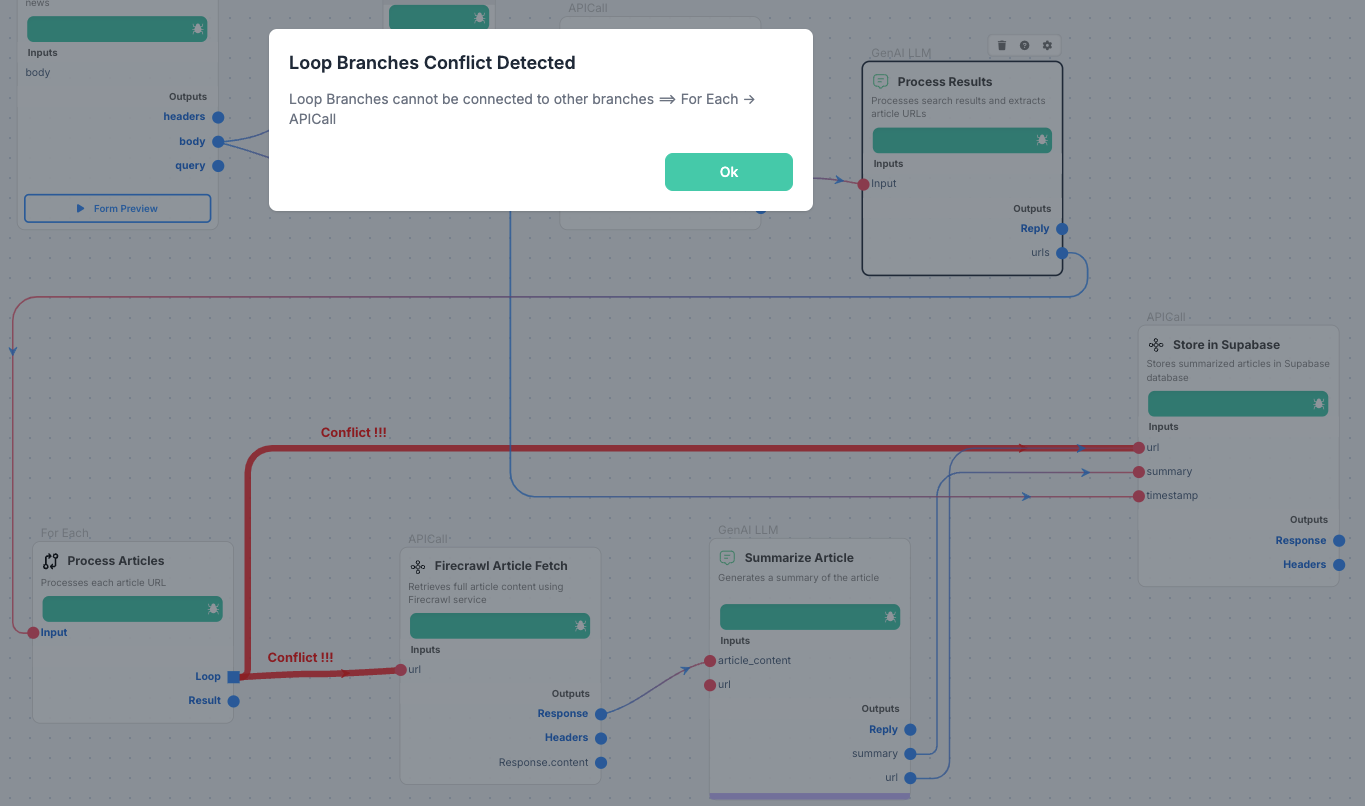
SmythOS: got tangled up in loops
SmythOS has an agent to help making the agents (see previous issue), but I could not for the life of me figure out how to do a basic loop. Support hasn’t got back to me yet either 🤷 Totally expect this to be fixed and I’ll update you.
Microsoft Autogen Studio 0.4.7: has a Deep Research template.
Autogen Studio as it is is a much more technical solution currently.
It’s an open source project that runs on your machine locally and you need to be comfortable with command lines, API keys and that kind of thing.
I cover it because because a) I fully expect autogen to be a hosted Azure solution eventually, and b) autogen offers a few unique things of the things that make it very appealing:
It has a visual builder but also generates code that can be deployed elsewhere (autogen agents can be written with no UI at all; the UI is a layer on top)
It has a really nice visual trace feature for tracing task execution.

Gumloop: promising
Another product rapidly evolving. I got basic scraping working fairly easily and the Gummie agent was absolutely instrumental to this as I pretty much just asked it what to do.
There are some connectivity issues (my Google Sheets destination just failed I’m sure it’s easy to fix, and the CSV writer kept writing JSON files again likely an easy fix).


Making my own CrewAI deep search agent in python with Windsurf Cascade and Claude 3.5 Sonnet
Ok now we’re REALLY rolling up our sleeves with a hands-on attempt to use CrewAI to build the agent.
CrewAI is another AI agent biggie:
it has a programming toolkit and command line support for running crews of agents
It offers a GUI called CrewAI studio but as far as I can tell it can’t be run locally so I didn’t use it for this project.
Here’s how it normally goes making a CrewAI crew:
Go through the tutorials and howtos to learn the CrewAI concepts and the command line tooling required to create and run crews.
Write all the code
Run it
This is what I did below. I’m so lazy 🤣
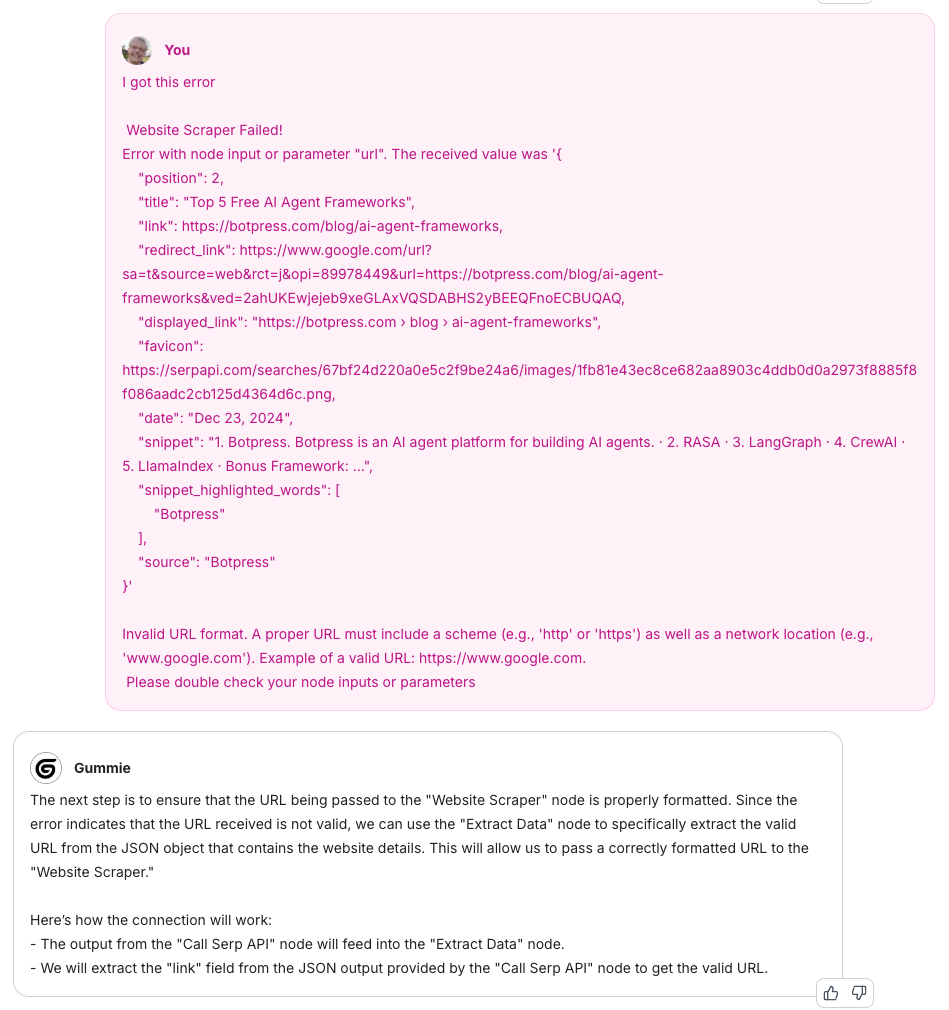
I asked Grok Deep Research to explain to me what the “Deep Research” algorithm is
I then asked it to “compare and contrast the various deep research open source projects out there on GitHub”. I have a list of these so I could compare.
It missed HuggingFace’s one so I asked it to add it, which it happily obliged.
I then asked “Ok create a state of the art deep research team using the crewAI.com framework: what the crew, agents and tasks should be to be state of the art.”
It generated some crews.
Looking at the code it generated for crewAI I wasn’t super convinced it’d work so I thought I’d take another tack. I asked this:
using all the research so far, reconcile it to create a mutually exclusive, comprehensively exchaustive specification for what a deep research agent team be, how they interact and what they should proudice. This should not be specific to a particular agent framework, but a general one that can be customised for a specific framework by simply adding "do this for <framework x>".
I then created a markdown file that captured this and inside Whisper + Claude Sonnet 3.5
I asked it to create a Crew based on the spec. It failed miserably and got really tangled up.
So I asked it to create a generic crew and then modify it according to the spec, and that seemed to work.

Using Windsurf’s conversational coding agent Cascade to create a CrewAI crew using just plain English was a breakthrough for me.
It even helped me revise the output to include URLs (as v1 didn’t).
Thank you for reading this far. I’d love to get your feedback: fill in the poll below!
Your vote matters…
Have your say! ✍️ 💬
Want this to be the best newsletter ever? I’d love to get your feedback.