
I built an agent from scratch to dispel their mystique. They're actually really simple.
In the next few issues I'll cover agents from the ground up, then compare it against frameworks to really drill down into the value agent frameworks bring (and don't bring).

This issue is made with care, attention, and original, hands-on technical research — and a little bit of obsession — as my curiosity got the better of me and I fell down a deep rabbit hole this issue.

Sometimes my newsletters are issued at strange times because of th is.
I apologise for the irregularity: but I do promise every time it’s packed full of unique and valuable insights that inspire, inform and now and then entertain.
Hopefully the wait is worth it for you.
Welcome back then to my humble corner of obsession:
Making AI Agents.
The mystique is palpable. Just wave your magic wand and your little robots will do your bidding!

I'm going to build one, step by step, so you can see how the goose lays its golden eggs.

With this approach I hope to dispel any hand-wavy mystique that agents may have for you, with some very real, very specific technology.
The exciting thing is that at their core, agents are very straightforward. Sure, they use technology that 10 years ago was pure science fiction, but that’s what makes them magical.
My definitions:
The very simplest AI agent is software that makes its own plans, and makes decisions based on those plans. 👈 this article is about this one
The next simplest one is software that also learns from those plans to make better ones. Future articles will cover this more powerful agent type.
This issue covers the first one.
Spoiler alert, a lot of the agent magic is prompt engineering, and in this issue specifically, we cover the “ReAct” (Reason & Act) prompt pattern:
You should follow the ReAct pattern:
1. Thought: Reason about what you need to do next
2. Action: Use one of the available tools
3. Observation: Review the results of the tool
4. Repeat until you have enough information to provide a final answer
But before that, here are a few must-read articles.
You can pretty much take it as a given that every week or two there are new brains (language models) to use for our agents. It’s an exciting time for agent brains. And the past couple of weeks week is no different.
Gemini Pro 2.5 Pro is a truly astonishing AI brain. My tests on code generation, particularly front-end visualisations were the best I’ve seen (so far). You can see it actually: I created interactive 3D visualisation of my agent in the issue, “vibe-coded”, simply by pasting the source code and having a fairly short conversation. 🤯
CopilotKit is a way to build in-app agents into any React app. I predicted this in this past issue of MAIA actually thought can it be a prediction if it already existed and I just didn’t know about it? 🤔 A postmonition maybe (opposite of a premonition).
Firecrawl is on fire: firecrawl is a web scraping service on steroids. It now has a new method called “deep research” which is basically an agentic web crawler as a service. See a real estate agent demo.
Julep has launched Open Responses: Julep is one of the 100+ agent maker frameworks out there and Open Responses is an open source clone of OpenAI’s “Responses” API. Things I like Responses for is:
Built-in tools (web search, file search, and computer use), and very interestingly,
Sessions. That is, rather than sending the message structure every time (like my agent in this article does) but it manages sessions on the server (like normal software for the past 40 years).
On to my agent, with a problem to solve.
The tech writer knowledge issue
Here's my problem: both the AI coding agents and myself struggle to extract useful knowledge from a code base. For instance:
"I want a quick way for new developers to on-board into the project. So a maintenance and new starters guide." 👶
"I want an architecture overview in a standard way I can compare with other products we have" 🏢
"I want a comprehensive list of all the use cases currently supported"
"I want to know what conventions, standards and technologies are used."
How do I improve my AI coding agent’s memory of what the code base does? (such as Windsurf, Cursor, Cline, Replit, Lovable etc).

Introducing the tech writer agent.
You give the agent your tech writing assignment and a code base.
It prepares a report uniquely taylored to your specific needs.
Here's a demo of the agent in action.
That's the big picture, now let's lift the hood on this thing.
My tech writer agent is single python file using no agent libraries, so if you’re impatient, here’s the full source, hand-written from scratch (by one of my hard-working AI coding agents of course 😉 — but no agent libraries I promise!)
The tech writer agent under the hood
Structurally, the tech writer agent is incredibly simple:
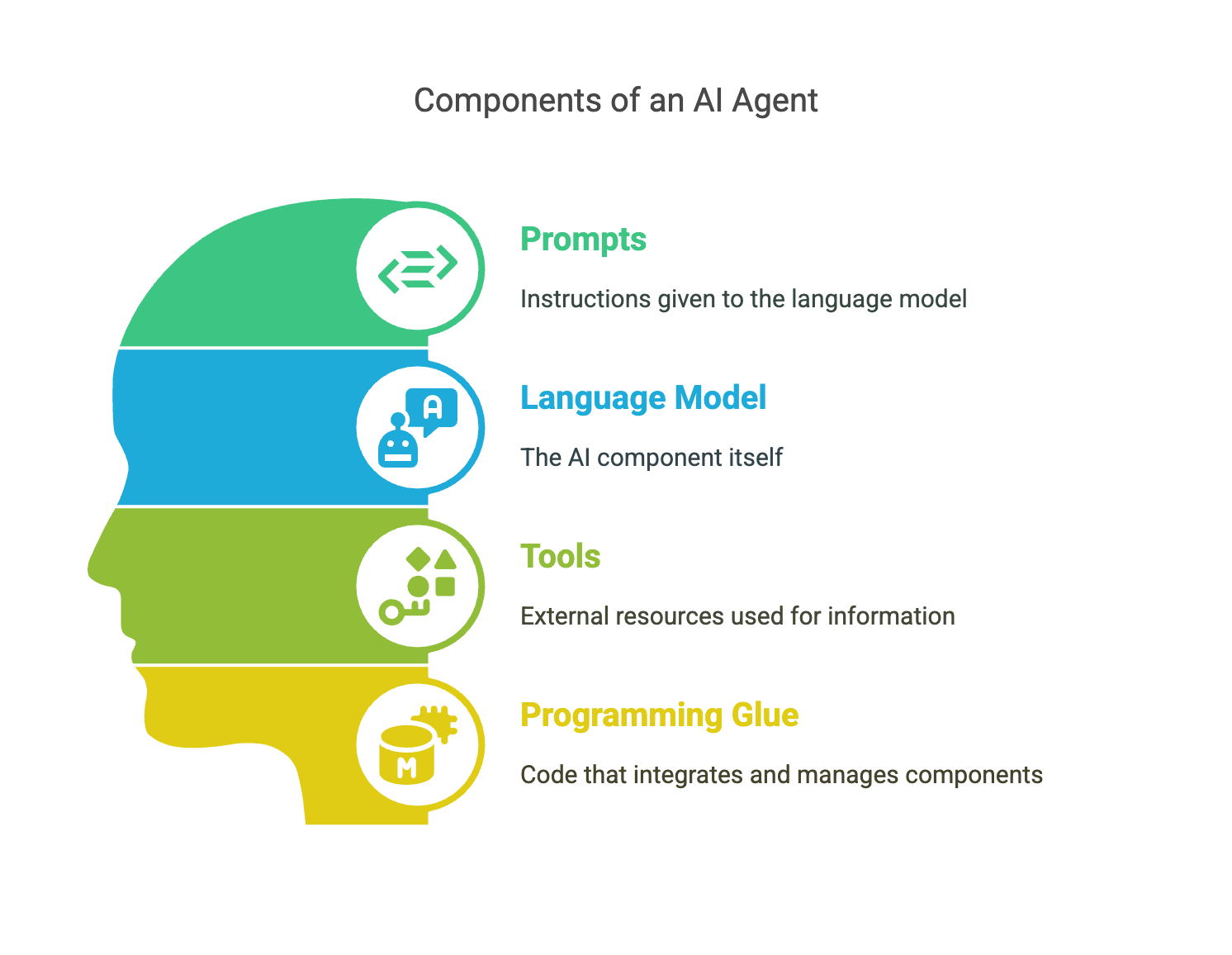
Prompts: the plain English instructions we give to the language model
Language Model (LM): the AI part.
Tools: special functionality the language model uses to get extra information. Local files, web searches, sheep prices in New Zealand, that sort of thing.
Programming Glue: code to to hold it all together, including ordinary Python variables for to give the agent temporary working memory.
Procedurally, it is also incredibly simple.
Assemble the prompt
Set up tools that can be used (in our case just three: file search, file access, and calculator)
Initialise our short term memory (spoiler alert: arrays of strings)
Then send a request to the language model with those bits above
Run any tools the language model asks us to run, add the tool output to memory and repeat
If the language model has decided it's done enough, then save the result to disk.
That's it.
Wait, a boring static picture? Naaah we can do better than that! Here’s a simulation of the agent’s workflow. Honestly it is overkill but I wanted to see how much I could get away vibe coding this baby.
It’s quite hard to follow on a small screen so save it for later when you’re on a desktop. (I hope to share the source to this but I hit some issues with Replit. I’ll let paying members know when it’s available 🙂)
Prompts: instructions to the language model.
Prompts appear innocently as “just text” but in fact, prompts are exceptionally powerful tool for communicating instructions to agents.
In my tech writer agent I’ve created clear sections for each purpose.
Honestly it’s mostly to help communicate to you, dear reader, what’s going on, but at its most basic level, it’s very useful to separate the ReAct part from the other parts (you’ll find out why in a future issue!)
Is there a best way to create prompts?
Is there… a perfect prompt? 🤨
There are certainly volumes of material on prompt engineering strategies, none of which I read 🙂. Here’s my guidance:
Test and evaluate different prompts.
For qualitative improvements, use more AI, repeatedly testing, evaluating and improving until the prompt doesn’t seem to change significantly. I cover this approach in a future issue actually! It’s quite remarkable and very simple. Like and subscribe, baby!
The important part of the prompt
REACT_PLANNING_STRATEGY
This is the magical part. I’m going to spend most of my time on this one. I already included it but I’ll include it again because it’s THAT important:
You should follow the ReAct pattern:
Thought: Reason about what you need to do nextAction: Use one of the available toolsObservation: Review the results of the toolRepeat until you have enough information to provide a final answer
Is this the ultimate ReAct prompt? Actually I did do some research on this and it could potentially be made a lot simpler. Potentially down to this:Answer the question by reasoning step by step and using tools like <tool x> or <tool y> if needed
I’ll leave that as an exercise for you to try out if you feel so inclined 😉
Oh and if you’re curious, here’s some meaty research that came up with the ReAct prompt from 2022.
And yes, there have been improvements — stay tuned for that in another issue!
The other parts of the prompt
This stuff is way more arbitrary and you can just let the prompts wash over you like a warm relaxing shower 🚿, with your eyes closed even.
ROLE_AND_TASK
This really sets the solution space: This is the exact prompt:
You are an expert tech writer that helps teams understand codebases with accurate and concise supporting analysis and documentation.Your task is to analyse the local filesystem to understand the structure and functionality of a codebase.
GENERAL_ANALYSIS_GUIDELINES
Follow these guidelines:
Use the available tools to explore the filesystem, read files, and gather information.Make no assumptions about file types or formats - analyse each file based on its content and extension.Focus on providing a comprehensive, accurate, and well-structured analysis.Include code snippets and examples where relevant.Organize your response with clear headings and sections.Cite specific files and line numbers to support your observations.
INPUT_PROCESSING_GUIDELINES
Important guidelines:
The user's analysis prompt will be provided in the initial message, prefixed with the base directory of the codebase (e.g., "Base directory: /path/to/codebase").Analyse the codebase based on the instructions in the prompt, using the base directory as the root for all relative paths.Make no assumptions about file types or formats - analyse each file based on its content and extension.Adapt your analysis approach based on the codebase and the prompt's requirements.Be thorough but focus on the most important aspects as specified in the prompt.Provide clear, structured summaries of your findings in your final response.Handle errors gracefully and report them clearly if they occur but don't let them halt the rest of the analysis.
CODE_ANALYSIS_STRATEGIES
When analysing code:
Start by exploring the directory structure to understand the project organisation.Identify key files like README, configuration files, or main entry points.Ignore temporary files and directories like node_modules, .git, etc.Analyse relationships between components (e.g., imports, function calls).Look for patterns in the code organisation (e.g., line counts, TODOs).Summarise your findings to help someone understand the codebase quickly, tailored to the prompt.
QUALITY_REQUIREMENTS
When you've completed your analysis, provide a final answer in the form of a comprehensive Markdown document that provides a mutually exclusive and collectively exhaustive (MECE) analysis of the codebase using the user prompt.
Your analysis should be thorough, accurate, and helpful for someone trying to understand this codebase.
Language model
This is not the language model itself, but it’s basically some glue code. You could say rather grandly “orchestration” but really it’s just a loop, some variables for memory and some API calls.
The important part.
run_analysis
THIS IS IT.
This is the loop that drives the agent as we know and love.
We limit the number of steps to something sensible (it’s set to 15 in my code but 6 or 7 is probably fine) but basically it does this:
Prompt to memory: language models have no memory by themselves so we need to keep track of all activity and repeatedly send it back to avoid instant amnesia. So we set up an a “memory” (an array, let’s be honest) with
All the system prompts mentioned, slammed together, then
Loading it up with the end user’s request
Code base location to memory: it then also adds to the memory where the code is on disk.
Then it loops around:
Give the language model its memory. It’s always thankful.
The language model’s response is only one of two things:
Final answer: we can stop and write the report which is helpfully contained entirely in the “content” part of the response.
Run some tools. The language model response obligingly includes parameter values too (e.g. which directory to search, which file to open).
When we have tools to run, the results of the tool calling is added to memory.
That’s it.
The less important stuff.
call_llm
Just a robust wrapper for calling OpenAI. Nothing to see here.
check_llm_result
This is exceptionally simple and probably badly named. If the OpenAI response has some tool calls to make, then that’s what it asks to do. If no tool calls are present, it assumes that we have a final result. Turns out this is fairly reliable (like, always, in my experience).
Tools: allowing language models to access the real world.
The most interesting tool functoin
execute_tool
The language model response is a JSON structure telling us what tool to call and with what parameters. This function figures out which tool to use (it’s really not hard, it’s a map).
Various agent frameworks have glue that do automatic mapping to python functions.
I don’t have that luxury so I do did it manually with a setup function called create_openai_tool_definitions. (Ok I lie, Windsurf + Claude 3.5 wrote all the code so it wrote this function by sniffing around in Langgraph to see how it did it and pulled bits out — all I had to do was encourage it to think like that 😉)
The workhorse tools
These are the interfaces to the rest of the world. For a code base analysis tool we really don’t need much: finding files, and opening them up. I threw in calculate too in case it needed to do some calculations.
find_all_matching_files
read_file
calculate
Why can’t the language model calculate itself?
Because it’s a token prediction system.
Yes it does billions of calculations a second to predict those tokens, but for specific calculations you need a tool.
You can certainly ask a language model to do maths, but once you go past you ten times table it gets really shakey. Because patterns (although an interesting article by Anthropic suggests it’s more intelligent than we thought).
Programming glue
Really almost nothing to see here. 🥱
analyse_codebase
Read the prompt file
Run the analysis
save_results
Write a markdown file to disk, that’s it.
So that’s it.
It was that simple. Ok well maybe not super simple but in the grand scheme of things, the power agents offer compared to the code required to write them is truly, truly remarkable.
Prompts with clever looping in them
Tools to do the actual work
Language model to decide which tools
And a few lines of “glue code” bringing it all together.
What’s missing then?
Heaps. But I think that’s enough for now and I’ll leave you with some questions:
Is ReAct the best prompt? 😯
How do different language models affect the quality?
Can multiple agents help? I heard about “LLM as a Judge”? Would that help?
How can an end user improve their prompt?
Plus a lot, lot more!
See you next time!
Thanks :-)